Visualizing Datasets
Study variable correlations with matplotlib and seaborn, and use dimensionality reduction (PCA, t-SNE) to display complex datasets.
Machine learning algorithms are complex, and many things can go wrong if you don't know what you're doing.
So a perfect recipe for disaster would be to pick up a dataset and blindly throw deep learning at it.
Before you can use machine learning on a dataset, you need to look at it to clean the data (e.g. to remove outliers), to select the most relevant variables, and to understand its topology to be able to select an adapted machine-learning algorithm.
If you don't do that, it's garbage in, garbage out:

In this post, you will learn how to:
- use matplotlib and seaborn to study simple, low-dimensional datasets.
- perform dimensionality reduction to display very high-dimensional datasets such as image datasets.
First, I'll describe the two datasets we'll take as examples, namely the simple Iris dataset, and the complex MNIST Handrwitten digits dataset. And I'll introduce the techniques we're going to use:
- Variable correlations
- Principle component analysis
- t-SNE
Then, you'll see how to visualize these datasets in a jupyter notebook.
This post is part on my introductory course to machine learning. If not yet done, you might be interested in the previous articles:
The Iris Dataset
The Iris flower dataset is one of the most famous machine learning datasets. It was introduced in 1936 by Fisher, in his paper "The use of multiple measurements in taxonomic problems" , as a practical example for the use of the Fisher discriminant.
It contains data collected for 150 specimens of three species of Iris flowers:
- Setosa
- Versicolor
- Virginica
And for each iris, we have four measurements, all expressed in cm:
- the sepal length
- the sepal width
- the petal width
- the petal length

So this dataset is indeed very simple, as it has only four variables.
Each Iris can therefore be seen as a point in a four-dimensional space.
To visualize the dataset, we could do a scatter plot of the four variables for all iris flowers. But we can't barely conceive a 4D space so forget about a display...
A first technique consists in doing a scatter plot for each pair of variables like this:
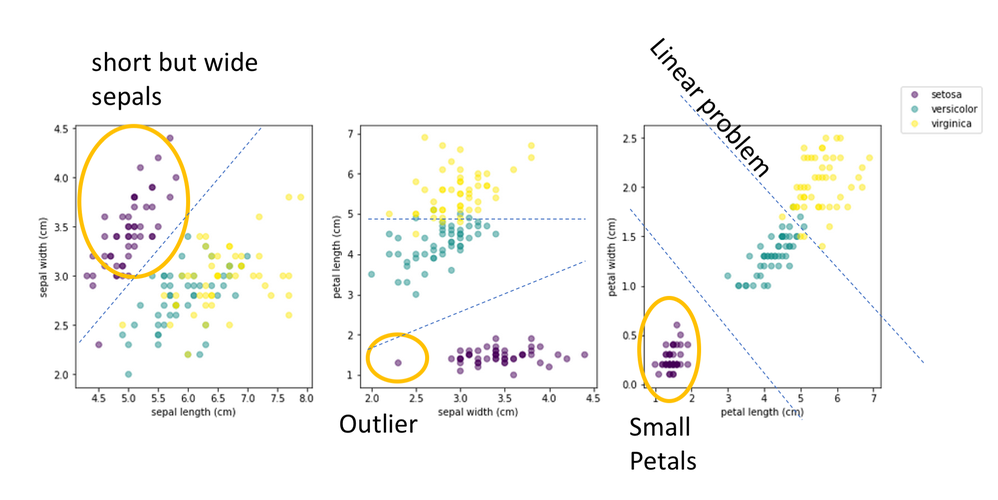
In this figure, I've done a scatter plot of three pairs of variables: sepal width vs sepal length (right), petal length vs sepal width (middle), and petal width vs petal length (right). And we can already interesting features.
First, Setosa looks very different from the other species. It has short but wide sepals, and small petals. Second, there is an outlier in the setosa sample, with surprisingly narrow sepals. Third, we see that we can classify the species by just drawing separation lines in these plots. This indicates that this classification problem is linear, and that one could use a simple logistic regression to classify irises. Finally, in the right plot, we see that a simple linear combination of only petal width and petal length would be enough to reach excellent classification accuracy.
As you can see, proper visualization gives us a lot of insight on the dataset.
But for high-dimensional datasets (with lots of variables), we're not going to be able to plot pairwise correlations like this. The first reason is that the number of combinations is exploding with the number of variables n as the combination (n, 2). So with 100 variables, you get 4950 pairwise scatter plots to analyse. And anyway, the more variables, the less information is carried by each pair of variable so these pairwise scatter plots won't be very instructive.
So what can we do? This is the subject of the next section.
The MNIST Handwritten Digits Dataset
The MNIST Handwritten Digits Dataset contains images of 70 000 handwritten digits, provided by Yann Le Cun et al. Each image has 28x28=784 pixels, and each pixel stores a unique value, corresponding to the grayscale level in the pixel.
This time, we therefore have one variable per pixel, and each image is a point in a very high-dimensional space with 784 dimensions. Single variable distributions and pairwise correlations are completely meaningless and unmanageable.
But the 784D space is mostly empty after all. If you select a random point in this space, you'll just get an image full of random noise most of the time.
But it could be that real images actually live on manyfolds of much lower dimension curving in the 784D space. For example, here are 1D manyfolds in a 3D space:
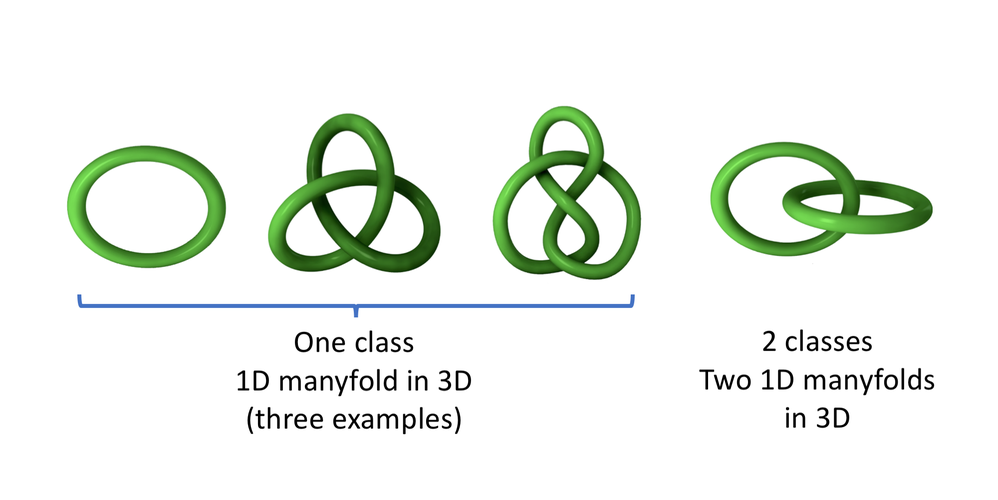
t-SNE is an unsupervised topology learning algorithm that is able to find the low-dimensional manyfolds in the original high-dimensional space, and to project these manyfolds in a destination space of much lower dimension, typically 2D or 3D:

The t-SNE algorithm was invented by van der Maaten and Hinton, and is described in their paper in Visualizing Data using t-SNE.
For a very good introduction to dimensionality reduction algorithms, including t-SNE, I suggest you to have a look at this excellent article from Chris Olah: Visualizing MNIST: An Exploration of Dimensionality Reduction.
And finally, before moving on, I strongly encourage you to play with t-SNE on simple datasets on this Distill article from Martin Wattenberg and Fernanda Viégas: How to User t-SNE Effectively.
Running this notebook
You can run this notebook on Google Colab by clicking here.
Visualizing a Simple Dataset¶
The Iris Dataset¶
The Iris dataset ships with scikit-learn. We start by loading the dataset:
import sklearn.datasets
dataset = sklearn.datasets.load_iris()
The resulting dataset object is a dictionary which contains:
- the data: sepal length, sepal width, petal length, petal width, all in cm, for each iris example
- the ground truth (or target, or label) for each iris example
- the variable names
- the target names
Here is a printout of this dictionary. Take a bit of time to look at it:
dataset
Let's extract the important information as local variables:
import numpy as np
data = dataset['data']
labels = dataset['target']
var_names = dataset['feature_names']
target_names = dataset['target_names']
print(var_names)
print(np.unique(labels))
print(target_names)
So examples with label 0, 1, and 2 correspond to setosa, versicolor, or virginica, respectively.
When the dataset only has a few number of variables, which is the case here (we have only 4), it is very instructive to plot the distribution of each variable, and the correlation between any pair of variables.
Plotting variable distributions with matplotlib¶
We want to make four plots, one per variable.
And in each plot, we will overlay the histograms corresponding to the three categories of examples.
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(10,10))
# loop on variables
for i in range(4):
# create subplot
plt.subplot(2,2,i+1)
# select the variable of interest from the data
values = data[:,i]
# define histogram binning.
# we use 20 bins between the minimum and maximum values
bins = np.linspace( np.min(values), np.max(values), 20)
# loop on categories
for j in np.unique(labels):
# select values for this category
categ_values = values[labels==j]
# plot histogram
plt.hist(categ_values, bins, alpha=0.5, label=target_names[j])
plt.title(var_names[i])
plt.legend()

We start to see interesting features:
- the petal length and petal width variables are very discriminating, but it's less clear for the sepal length and sepal width.
- it's going to be easy to separate setosa, while versicolor and virginica look similar.
For more insight, we plot the correlations between pairs of variables:
fig, axs = plt.subplots(1,3, figsize=(15,5))
for i in range(3):
j = i+1
# we plot variable 1 vs 0, then 2 vs 1, then 3 vs 2
scatter = axs[i].scatter(data[:,i], data[:, j], c=labels, alpha=0.5)
axs[i].set_xlabel(var_names[i])
axs[i].set_ylabel(var_names[j])
elems = list(scatter.legend_elements())
# by default, the legend labels are the values
# of the target, 0, 1, 2.
# we replace that with the target names:
elems[1] = target_names
fig.legend(*elems)

Before discussing these plots, let's see how they could be done more easily, and made prettier.
Plotting variable distributions with Seaborn¶
With matplotlib, it's possible to do almost any plot, and we did get our plots.
But as you have seen, it's not that easy, and it often requires a dozen lines of code or more.
Fortunately, higher-level libraries like Seaborn exist. In this section, you will see how to use seaborn to plot pairwise relationships in the dataset.
We first need to install a recent version of seaborn, at least 0.10.0). That's only done if you don't have it already:
%%capture
%pip install seaborn==0.10.0;
Seaborn is closely interfaced to pandas, which is the probably the best data-analysis and data-crunching library in python. This tutorial is not about pandas, so I'm not going to give you any details. For now, you just need to know that pandas dataframes turn your data arrays into some kind of Microsoft Excel tables.
But contrary to Excel, pandas can handle millions of rows, it's way faster, and it's fully integrated with python by construction.
So we create a dataframe from our data array, giving a name to each column in the array:
import pandas as pd
df = pd.DataFrame(data,
columns=['sepal_length',
'sepal_width',
'petal_length',
'petal_width'])
And we add the corresponding labels as an additional column before printing the dataframe:
df['species'] = labels
df
Now that we have the dataframe, we can create a pair plot with Seaborn in just one command!
import seaborn as sns
sns.pairplot(df, hue="species", palette='bright');

If you don't see the full plot above, you can deactivate the scrollbar by doing Cell -> Current Outputs -> Toggle Scrolling.
Now we have a much clearer view on our dataset:
- Both petal_length and petal_width, even taken alone, are enough to perfectly isolate setosa (0). Indeed, it's enough to apply a simple threshold in the petal_length or petal_width histograms.
- They also provide rather good discrimination for versicolor vs virginica, though the distributions overlap in the histograms.
- In the scatter plot petal_length vs petal_width, we see that a linear combination of these variables provides the best separation between these close categories: you can just draw a straight line in the plot to discriminate them.
- sepal_length and sepal_width do not bring much
- sepal_width shows an outlier in the setosa class. Before training a machine learning model to classify irises based on all four variables, one should consider removing this outlier.
I encourage you to have a look at the seaborn tutorial and the seaborn API to see what exists before trying to implement a complex plot with matplotlib.
Principle Component Analysis (PCA)¶
We have seen that in the simple Iris dataset, the three classes can already be well separated by looking at only two variables, e.g. petal_length vs petal_width.
The variables petal_length and petal_width, taken together, seem to maximize the separation between the classes, and they could be called principal components. So in some sense, we already performed a simple principal component analysis visually.
But we were able to do that only because the Iris dataset is really simple.
in fact, in most datasets, the principal components do not correspond to the raw variables, but to combinations of the raw variables.
Also, for datasets with a higher dimensionality (with more variables), it's not possible to find the proper combination of variables leading to the principal components by eye.
And this is why we need PCA.
PCA starts with a dataset in an original ND space, meaning that it has N variables. Given the desired number of principal components n<N, PCA finds the n linear combinations of the N variables that maximize the total variance of the dataset in the destination nD space.
PCA on the Iris dataset¶
Let's see PCA in action on the Iris dataset.
First, we project the dataset from the original 4D space to 2D.
With scikit-learn, it's very easy to run PCA:
from sklearn import decomposition
pca = decomposition.PCA(n_components=2)
view = pca.fit_transform(data)
We can then check that our 2D view of the dataset indeed has two dimensions:
view.shape
And we can plot the dataset in the resulting 2D space, as a function of the two principal components
plt.scatter(view[:,0], view[:,1], c=labels)
plt.xlabel('PCA-1')
plt.ylabel('PCA-2')

PCA works, but it appears that PCA-1 and PCA-2 provide worse separation between the classes than petal_length and petal_width.
This is due to the fact that PCA maximizes the total variance of the full dataset, which is not the same as maximizing the separation between the classes!
Obviously, it would be better to maximize class separation, and this is precisely what Linear Discriminant Analysis (LDA) is doing. In case you've heard about Fisher's linear discriminant analysis, it's a kind of LDA.
But to perform LDA, you need to know the class labels, so LDA is a supervised learning technique.
So the advantage of PCA is that it can be used to lower dataset dimensionality even when the classes are not known; it is an unsupervised learning algorithm.
Illustration of PCA on a simple 3D dataset¶
To illustrate PCA visually, let's build a toy dataset with 3 variables and 3 classes. Each of the three samples follows a 3D normal distribution. The distributions are centred at the vertices of an equilateral triangle:
import sklearn.datasets
import math
a = 3
c = math.sqrt(2*a**2)
h = math.sqrt(3)/2. * c
data, labels = sklearn.datasets.make_blobs(n_samples=2000,
n_features=3,
centers=[[0,0,0],
[a,a,0],
[a/2, a/2, h]])
import mpl_toolkits.mplot3d.axes3d
fig = plt.figure(figsize=(10,10))
ax = fig.add_subplot(221, projection='3d')
alpha=0.4
ax.scatter(data[:,0], data[:,1], data[:,2], c=labels, alpha=alpha)
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_zlabel('z')
ax = fig.add_subplot(222)
ax.scatter(data[:,1], data[:,2], c=labels, alpha=alpha)
ax.set_xlabel('y')
ax.set_ylabel('z')
ax = fig.add_subplot(223)
ax.scatter(data[:,0], data[:,2], c=labels, alpha=alpha)
ax.set_xlabel('x')
ax.set_ylabel('z')
ax = fig.add_subplot(224)
ax.scatter(data[:,0], data[:,1], c=labels, alpha=alpha)
ax.set_xlabel('x')
ax.set_ylabel('y')

Take a moment to understand how this dataset is arranged in 3D.
In all three 2D views built from the raw x,y,z variables, the blobs overlap, and it's not possible to separate the classes.
PCA, on the other hand, flies around the dataset in 3D until it finds the best point of view:
view = pca.fit_transform(data)
fig = plt.figure(dpi=90)
ax = fig.add_subplot(111)
ax.scatter(view[:,0], view[:,1], c=labels, alpha=alpha)
ax.set_xlabel('PCA-1')
ax.set_ylabel('PCA-2')
ax.set_aspect('equal')

In this view, the separation is much better.
Again, take some time to find out from where PCA looks at the equilateral triangle in 3D.
Important facts about PCA:
- PCA is an unsupervised learning algorithm. It does not maximize class separation but total variance in the dataset;
- It is linear, so it preserves the distances between points of the dataset.
Visualizing the MNIST Handwritten Digits Dataset¶
The MNIST dataset comprises images of handritten digits between 0 and 9. Each image has 28x28 = 784 pixels, with a single grayscale channel for each pixel.
Let's download the full dataset from openml:
from sklearn.datasets import fetch_openml
raw_data, raw_labels = fetch_openml('mnist_784', version=1, return_X_y=True)
Here is some basic information about the dataset:
print(raw_data.shape)
print(np.max(raw_data))
print(np.unique(raw_labels))
We have 70 000 images. For each image, the grayscale values for each pixel are between 0 and 255, and are presented in a flat 1D array. The labels are provided as strings.
For what we want to do, 70 000 is way too much, so we're going to start by selecting a subset of the dataset:
nsamples = 5000
data = raw_data[:nsamples]
labels = raw_labels[:nsamples]
Then, we do a bit of preprocessing:
- normalize grayscale levels to 1.
- convert labels from strings to integers
- create an array of images for plotting, in which the 28x28 pixel structure is restored
data = data / 255.
labels = labels.astype('int')
images = data.reshape(data.shape[0], 28, 28)
Here are a few digit images:
plt.figure(figsize=(8,8))
for i in range(4):
plt.subplot(2,2,i+1)
plt.imshow(images[i])
plt.title('truth: {}'.format(labels[i]))

Each image has a given grayscale value in each of the 784 pixels. So each image is a point in a 784D space.
Do we have a way to reduce the dimensionality of this dataset to a manageable level, so that we can see whether the points have a tendency to cluster together depending on their class? Our brains can only visualize spaces with 3 dimensions or less, so we will need to project our points to their original 784D space to either a 2D or a 3D space.
PCA on the MNIST dataset¶
We start with a principal component analysis:
pca = decomposition.PCA(n_components=2)
view = pca.fit_transform(data)
plt.scatter(view[:,0], view[:,1], c=labels, alpha=0.2, cmap='Set1')

Some structure appears, and we are able to identify a few rather isolated clusters!
That's quite impressive, given the drastic dimensionality reduction we have applied (from 784 to 2 dimensions).
Still, most of the distribution remains confused, with some classes spread all over the place.
t-SNE on the MNIST dataset¶
With PCA, we have found the two linear combinations of the original 784 variables that maximize the total variance of the dataset, with mixed results.
The original 784D space is mostly empty: If we choose a point randomly in this space, we're just going a random value for each pixel, and a noise image.
Real images actually occupy a very small portion of the original space, and it is believed that they live on manyfolds of much lower dimension that curve around like ribbons in the 784D space.
If this is true, digits of a given class would be sitting on the same ribbon. If the ribbon only occupies a corner of the 784D space, PCA will show it as a cluster in the plane defined by the two principal components. But if the ribbon shoots through the entire 784D space, PCA is not going to be able to tell us much.
In this section, we're going to try and reduce the dimensionality of the dataset with t-SNE (t-distributed Stochastic Neighbor Embedding).
The theory of this algorithm is described in the original paper from van der Maate and Hinton. But it's not that easy, so for now, you just need to know that t-SNE attempts to preserve the topology of the original space:

Illustration of t-SNE projecting a 3D dataset to 2D. The dataset points live on 1D manyfolds (lines) in the 3D space. We consider a dataset with only 1 category on the left, and with two categories on the right.
We run t-SNE on the MNIST datasets to project from the original 784D space to 2D, as specified by the n_components argument.
from sklearn.manifold import TSNE
view = TSNE(n_components=2, random_state=123).fit_transform(data)
Then, we plot the dataset as a function of the two t-SNE components, coloring each point according to its label.
plt.figure(figsize=(20,10))
plt.scatter(view[:,0], view[:,1], c=labels, alpha=0.5)
plt.xlabel('t-SNE-1')
plt.ylabel('t-SNE-2')

It works! the 10 manyfolds corresponding to the digit categories are well separated by the transformation. But two classes remain intricated at the top. It's probably because the corresponding manyfolds are too close within the 784D space.
Before going further, I encourage you to play around with t-SNE on this excellent interactive web page from Wattenberg and Viégas.
Influence of randomness and perplexity¶
t-SNE is a stochastic process, so depending on the initialization of your random number generator, you'll get different results.
Also, t-SNE depends on an important parameter, perplexity, which describes how far the algorithm is going to look for neighbours in the original 784D space to consider them as belonging to the same manyfold.
If the perplexity is too low, noise and stastical fluctuations within a single class will lead to separate clusters in the destination 2D space. If it's too high, different classes will be grouped in the same cluster.
So it's important to try different values for the perplexity.
Exercise
Redo the t-SNE projection and display with different values for:
- random_state
- perplexity
Investigating individual points¶
In this section, we will build an interactive plot with bokeh. It will allow us to hover in the plot and find the digit image corresponding to a particular point so that we can display it.
Creating a plot in bokeh is not that easy. Here, I'm not going to explain everything, we just want to do the plot. So don't worry if you don't understand the code below. And if you want to learn bokeh, I suggest you to start with the bokeh interactive tutorial accessible from here, and with the following posts on thedatafrog.com
- Interactive Visualization with Bokeh in a Jupyter Notebook
- Show your Data in a Google Map with Python
First, we install bokeh (might not be needed depending on your platform):
%%capture
%pip install bokeh
from bokeh.io import output_notebook, show
from bokeh.models import ColumnDataSource
from bokeh.plotting import figure
output_notebook()
Then, we prepare a data frame with the data for the display:
import pandas as pd
df = pd.DataFrame(view, columns=['x','y'])
df['label'] = labels.astype('str')
df
# define hover tool
from bokeh.models import HoverTool
hover = HoverTool(
# we print the class label
# and the index in the dataframe
# in the tooltip
tooltips = [('label','@label'),
('index', '$index')]
)
# create figure
fig_scat = figure(tools=[hover, 'box_zoom', 'crosshair', 'undo'],
plot_width=600)
# bokeh data source from the dataframe
source = ColumnDataSource(df)
# color definition
from bokeh.transform import linear_cmap
from bokeh.palettes import d3
from bokeh.models import CategoricalColorMapper
palette = d3['Category10'][10]
cmap = CategoricalColorMapper(
factors=df['label'].unique(),
palette=palette
)
# scatter plot in figure
fig_scat.scatter(
x='x', y='y', alpha=0.5,
color={'field': 'label', 'transform': cmap},
source=source
)
# display below
show(fig_scat)
You can now zoom in the plot, and hover to get information on the points. Pick up the index for the point you are interested in, and display it like this:
index = 1598
plt.imshow(images[index])
plt.title(labels[index])

To make it a bit easier, let's write a small function to display easily a few points:
def plot_images(*indices):
if len(indices)>6:
print('please provide at most 6 indices')
return
fig = plt.figure(dpi=100)
for i, index in enumerate(indices):
fig.add_subplot(2, 3, i+1)
plt.imshow(images[index])
plt.title(labels[index])
plt.axis('off')
plot_images(0,1,2,3,4,5)

With the interactive display above, I selected two points which are very close and of different colors right of the middle of the 7 cluster:
plot_images(2909, 2125)

Pretty close aren't they? I guess this 2 has been considered as a member of the 7 manyfold by t-SNE because sometimes, sevens are written with a rounded top, and sometimes with a bar.
Exercise
- Select series of points in the interactive bokeh display and display them to get a feeling for the quality of the t-SNE projection.
Outlook and Acknowledgements
If you'd like to keep going with unsupervising learning, check out my Introduction to clustering.
Finally, I would like to thank Chris Olah for his great article Visualizing MNIST: An Exploration of Dimensionality Reduction. That's where I took most of the ideas for this post. I only added some information about how to use these techniques in python.
Please let me know what you think in the comments! I’ll try and answer all questions.
And if you liked this article, you can subscribe to my mailing list to be notified of new posts (no more than one mail per week I promise.)
Learn about Data Science and Machine Learning!
You can join my mailing list for new posts and exclusive content: